TL;DR Paragraph
I store EU industry production data in a PostgreSQL database using the SQLAlchemy package.
Long Description
Building on the previous project, I download an EU industry production dataset from the EU Open Data Portal, put it in a pandas dataframe, and store it in a PostgreSQL database. Using such a data store can be important for quick and reliable data access. The database is readily set up on my local computer and accessed from Python using the SQLAlchemy library. Pandas and SQLAlchemy work well together to ingest the dataset into the PostgreSQL database in merely a few lines of code, thus saving a lot of time and nerves.
Table of contents
Project Background
Instead of redownloading data from the original source each time a dataset is used, it can be beneficial to store it locally. One advantage is the persistence of the local data store – it is not necessary to worry about the original data source being removed from the repository. In addition, large datasets can take a long time to download and generate a lot of traffic. Data access can be sped up considerably by storing it locally.
A typical form of data stores are relational databases. In a relational database, data is stored in the form of a collection of tables (similar to a pandas dataframe). One powerful feature of relational databases is the possibility to combine information from different tables as needed. For example, in a company’s revenue database, one table might contain a list of orders (with customer id, item id, amount paid, date, billing number etc.), while other tables might contain information about the customers (customer id, customer name, address, etc.) or products (item id, item name, category, price, etc.). So the orders table contains information about the customers and items in condensed form of an id, thus avoiding redundant information and saving disk space. The full information can be obtained by joining the orders table with the customer and product tables in a database query, on demand. Queries are carried out in a specific language, one of which is SQL (Structured Query Language). There are various flavors of SQL, including MySQL, PostgreSQL and others.
In this project, I will set up a PostgreSQL database on a Windows 10 machine, connect to the database from Python using the SQLAlchemy package and ingest the EU industry production dataset from a pandas dataframe.
Setting up PostgreSQL
Let’s start by downloading and installing the current version of PostgreSQL (9.6.5), following this tutorial. During installation, I have to create a password for the default superuser “postgres”. When the setup program has finished and a PostgreSQL server is running on the localhost, I start the graphical tool “pgAdmin 4” to monitor the server and create a new database. The latter is done with “Object -> Create -> Database”:
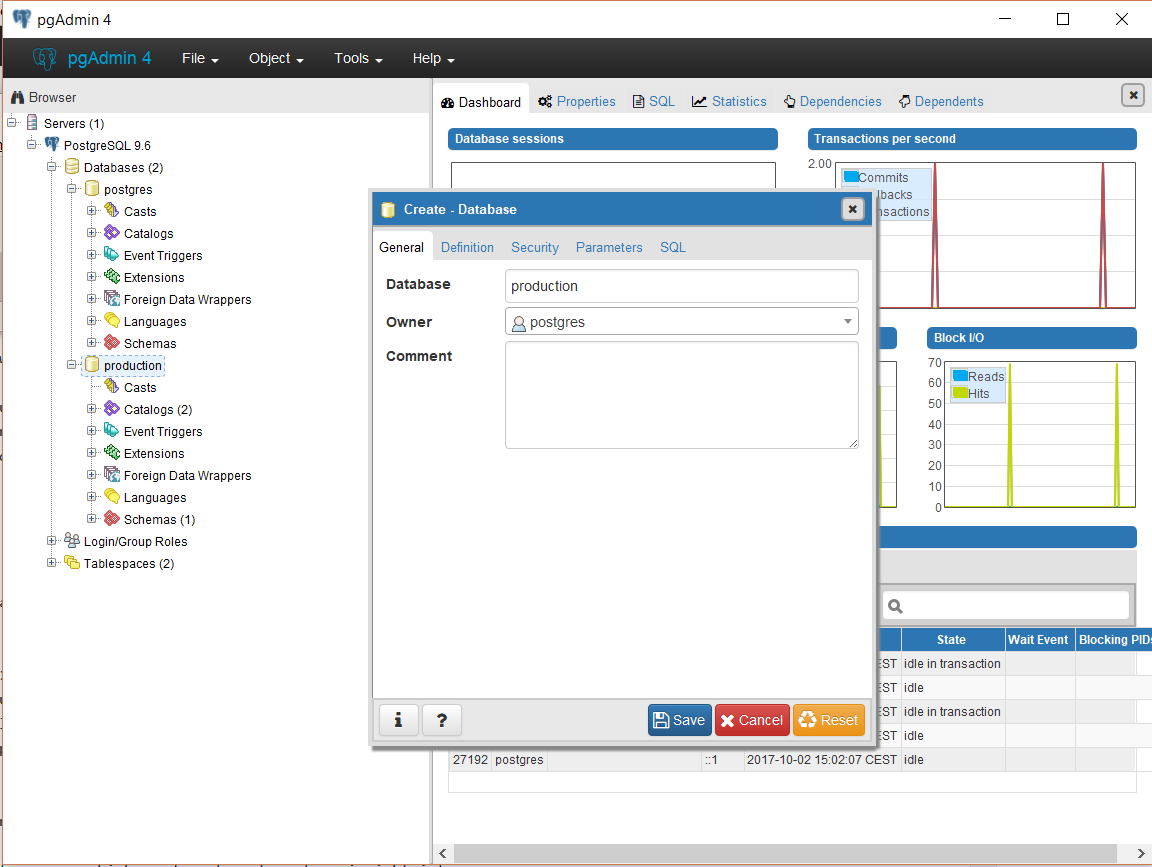
I choose the name “production” for the new database and “postgres” as the owner.
Downloading the dataset
It’s time to get the data that I will store in the database. From the previous project, I know how to import the dataset into Python:
import pandas as pd # Package for organizing datasets in dataframes
# URL of dataset (EU industry production data)
dataset_tsv_url = 'http://ec.europa.eu/eurostat/estat-navtree-portlet-prod/BulkDownloadListing?file=data/sts_inpr_m.tsv.gz'
# Read in dataset: From compressed TSV file directly to pandas dataframe
df = pd.read_csv(dataset_tsv_url, compression='gzip', sep='\t|,', index_col=[0,1,2,3,4], engine='python')
Connecting to the database
Now that the data has been loaded into a pandas dataframe, let’s connect to the freshly created database. A user-friendly tool to achieve this in Python is the SQLAlchemy package. Key to setting up the connection is the create_engine() method. It accepts a string that specifies the connection details in the following format: "databasedialect://user:password@host/database". In this case, the database dialect is postgresql, the username postgres with the password xfkLVeMj, the database server is running on localhost and the name of the database that I just created is production. Let me execute this code and check if there are any existing tables in the database:
import sqlalchemy # Package for accessing SQL databases via Python
# Connect to database (Note: The package psychopg2 is required for Postgres to work with SQLAlchemy)
engine = sqlalchemy.create_engine("postgresql://postgres:xfkLVeMj@localhost/production")
con = engine.connect()
# Verify that there are no existing tables
print(engine.table_names())
[]
The database is empty — as it should be at this stage.
Storing the dataset
Okay, the connection to the database is successfully established and the data is available in a pandas dataframe. Let’s finally ingest the dataset into the database! With pandas, this can be conveniently done with the to_sql() method. I only need to specify a name for the new table that will represent the dataset and pass the SQLAlchemy connection object con:
table_name = 'industry_production'
df.to_sql(table_name, con)
That was easy, eh? Let’s see if the table creation was successful:
print(engine.table_names())
['industry_production']
Apparently, the ingestion has worked! At the end, I should not forget to close the connection to the database:
con.close()
Conclusion
I have successfully set up a PostgreSQL database and filled it with the EU industry production dataset. The whole process was much easier than anticipated, owing to the powerful Python packages pandas and SQLALchemy as well as the uncomplicated PostgreSQL installation process. It wasn’t even necessary to explicitly use the SQL language.
Code
The project code was written using Jupyter Notebook 5.0.0, running the Python 3.6.1 kernel and Anaconda 4.4.0.
The Jupyter notebook can be found on Github.
Bio
I am a data scientist with a background in solar physics, with a long experience of turning complex data into valuable insights. Originally coming from Matlab, I now use the Python stack to solve problems.
Contact details
Jan Langfellner
contact@jan-langfellner.de
linkedin.com/in/jan-langfellner/
2 thoughts on “Storing a pandas dataframe in a PostgreSQL database”