I am a data scientist with a background in solar physics, with a long experience of turning complex data into valuable insights. Originally coming from Matlab, I now use the Python stack to solve problems.
Portfolio
This data science project portfolio contains 14 projects that together cover the entire data science workflow — from acquiring data to reflecting upon the outcome. The projects apply Python and SQL to solve problems; the packages/tools that are used encompass NumPy, pandas, PostgreSQL, scikit-learn, matplotlib, Jupyter, and others.
Projects: End-to-end
EU industry production — From an online dataset to a visualization of key trends
From the European Union Open Data Portal, I obtain data on the industry production growth in each EU member state and analyze which countries outperform the others.
Here is a link to the summary of the end-to-end project. Below you can find the individual projects for the single data science steps.
Projects: Individual data science steps
The end-to-end project is broken down into smaller projects that each focus on a single step of the entire data science process:
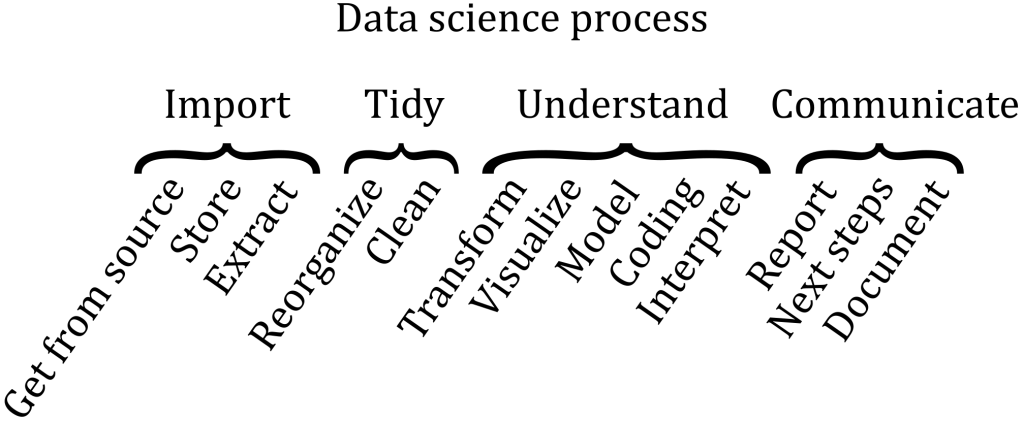
Credit: based on “R for Data Science” by Hadley Wickham, Garrett Grolemund and “Data Science Portfolio Guide” by Sebastian Gutierrez
Below is a list of these projects, in the order of the data science steps. Clicking on a project name brings you to the project write-up:
Import
Import data from original source or local data store
Import from source
Import data from an original source (data repository, API, etc.)
Automated data retrieval from an online repository to harness free data sources
I obtain monthly EU industry production data from the European Union Open Data Portal through an API.
Store
Store imported data in a data store (e.g., SQL database)
Storing a pandas dataframe in a PostgreSQL database
I store EU industry production data in a PostgreSQL database using the SQLAlchemy package.
Extract
Extract whole dataset(s) or specific parts from a data store (e.g., SQL database) and load into Python
Using SQL queries to extract data from a PostgreSQL database
Making use of SQLAlchemy and SQL queries, I extract EU industry production data for further analysis from the PostgreSQL database where I previously stored it.
Tidy
Reorganizing, combining and cleaning data so that it is ready for analysis
Reorganize
Reorganize and/or combine dataset(s) in a tidy form for analysis/visualization/modeling
Bringing an EU industry production dataframe into good shape
I use Pandas dataframe methods to bring EU industry production data into a tidy format to facilitate further analysis.
Clean
Treat data values: Identify missing data, fix data types, split values etc.
Making the numbers shine: Cleaning EU industry production index values
I make EU industry production index values, which I previously put in a tidy form, ready for analysis by splitting numbers and flag values with pandas methods.
Understand
Make sense of data with (iteratively using) statistics, visualization, data transformation and modeling
Visualize
Show trends and statistics of data in compact, human-friendly way
Exploring the industry production history with EDA
I use statistical and graphical tools to perform exploratory data analysis (EDA) on the EU industry production dataset as a starting point for modeling the time series.
Different countries’ growth dynamics at a glance with bar charts
I use pandas’ interface to the matplotlib library to create bar charts that visualize the manufacturing growth dynamics of European countries.
Transform
Prepare data for modeling: Feature engineering, value imputation etc.
Removing common trends from a set of time series to highlight their differences
I divide the EU industry production index time series for each country by the smoothed EU average time series to bring out the countries’ individual development for further modeling.
Model
Experiment design: Selecting model, metric and algorithm
Reducing complexity – from a time series to a single number: modeling
I select a linear model with slope and intercept parameters to describe the growth dynamics of the EU industry production index of each country.
Coding
Execution, iteration and finalization of modeling algorithm
Reducing complexity – from a time series to a single number: coding
Using the linear model from Python’s scikit-learn package, I obtain the slopes in the EU industry production time series for each country.
Interpret
Interpret results and draw conclusions
Spotting trends in the manufacturing growth dynamics: Which region grew the fastest?
I use the visualization of the EU countries’ manufacturing growth rate with a pandas/matplotlib bar chart to show that the performance mostly depends on geographical position: the East beats the South.
Communicate
Report project results, suggest next steps, document code
Report
Summarize and discuss project
What was the approach, what worked, what didn’t work, what assumptions were made, what would I do different, why do insights matter
EU industry production: From an online dataset to a visualization of key trends
I give a high-level description and discussion of the projects in this portfolio that deal with the analysis of the EU industry production dataset, from finding the data to possible next steps.
Next Steps
Possible next projects that build on/complement current project
Where to go from here: A more comprehensive study of economic growth
I discuss the scope of the analysis of the EU industry production dataset and point to possible extensions with additional datasets.
Document
Code and steps that are necessary for replication
Software and Jupyter notebooks for the industry production analysis
I specify the software versions that I used for the analysis of the EU industry production dataset and provide links to the Github repository where the Jupyter notebooks are stored.
Contact details
Jan Langfellner
contact@jan-langfellner.de
linkedin.com/in/jan-langfellner/